
AI PC真的准备好了吗?
和AMD高管聊完,我对“完美PC”有了新的判断

AMD高级副总裁,计算与图形事业部总经理Jack Huynh与本刊记者合影
正是在这样的背景下,今年CES期间,我们有幸约到了AMD高级副总裁,计算与图形事业部总经理Jack Huynh,在了拉斯维加斯Palazoo酒店一起交流沟通。与其说这是一次例行的媒体采访,不如说更像是一次围绕AMD近期技术取向与产品节奏的阶段性复盘。在CES这一节点上,AMD既需要回应外界对AI PC的期待,也须解释一下Strix Halo、锐龙AI 400系列+以及NPU路线背后更长期的判断。
eFashion:我们看到Strix Halo尤其是锐龙AI MAX+ 395这款产品,在中国催生了大量的产品形态,主要是迷你 AI工作站(Mini AI Workstation),请问未来针对这款产品有什么支持和新品规划?

谈到Strix Halo与旗舰型号锐龙AI MAX+ 395的时候,Jack Huynh的语气非常直接——这是一个超出最初预期的产品平台。他回忆道,在锐龙AI MAX系列首次发布时,AMD的判断其实是在尝试开辟一个全新的类别:既不是传统意义上的移动处理器,也不只是游戏或工作站的单一定位,而是希望在游戏、工作站与AI计算之间建立一种统一的平台能力。

这一尝试的核心基础,是AMD在x86平台上率先实现的UMA统一内存架构。通过让CPU、GPU以及AI引擎 NPU共享同一套高带宽内存资源,Strix Halo不再需要在不同计算单元之间频繁拷贝数据,这为本地AI推理和高并行计算提供了极大的效率优势。
Jack指出,在过去6到12个月中,这一平台在中国市场的增长速度非常快。从最初的两种平台方案,迅速扩展到了30多种不同的设计形态,涵盖了从笔记本、桌面设备到多种Mini PC和Mini AI Workstation的形态组合。尤其是在Mini AI Workstation这一细分方向上,中国市场展现出了极强的创新能力和接受度。

值得注意的是,Jack特别强调,Strix Halo并不只是一个“性能很强的游戏盒子”,而是在此基础上同时具备了非常完整的AI计算能力。这一点在产品形态的多样化上已经得到了印证。从强调体积和能效的迷你主机,到追求极致算力密度的小型工作站,背后依托的都是同一套平台能力。
在性能演进层面,Jack给出了非常具体的时间线:最初发布时,锐龙AI MAX平台支持的模型规模大约在70B参数级别(约140GB),随后通过持续的优化提升到了128B(约256GB),而在最新阶段,已经能够支持200B级别(约400GB)的参数模型。这种提升并非简单依赖硬件更新,而是通过架构、内存调度以及软件栈共同演进实现的。
软件层面同样是Jack反复提及的重点。Strix Halo平台原生支持Linux和Windows,并且深度依托AMD在ROCm软件体系上的持续投入。AMD正在做的,并不是为某一款芯片单独优化,而是将ROCm软件栈同步铺开到整个产品线中,使得开发者在AMD平台上运行AI工作负载时,可以真正做到“开箱即用”。就在本次CES上,AMD宣布最新版本的ROCm 7.2已经将支持范围扩展到新发布的锐龙AI 400系列移动处理器。

从行业角度看,Strix Halo在中国市场催生Mini AI Workstation繁荣的现象,本质上反映了一个现实需求:本地可负担的AI算力正在成为新的生产力工具。在性能、价格与能效之间,锐龙AI MAX+ 395正好落在了一个对开发者和企业都极具吸引力的区间,这也是Jack提到“性能/价格比在市场中极具竞争力”的原因。而本地化部署的另外一大优势就是,可以保护隐私和敏感数据。
eFashion Says:
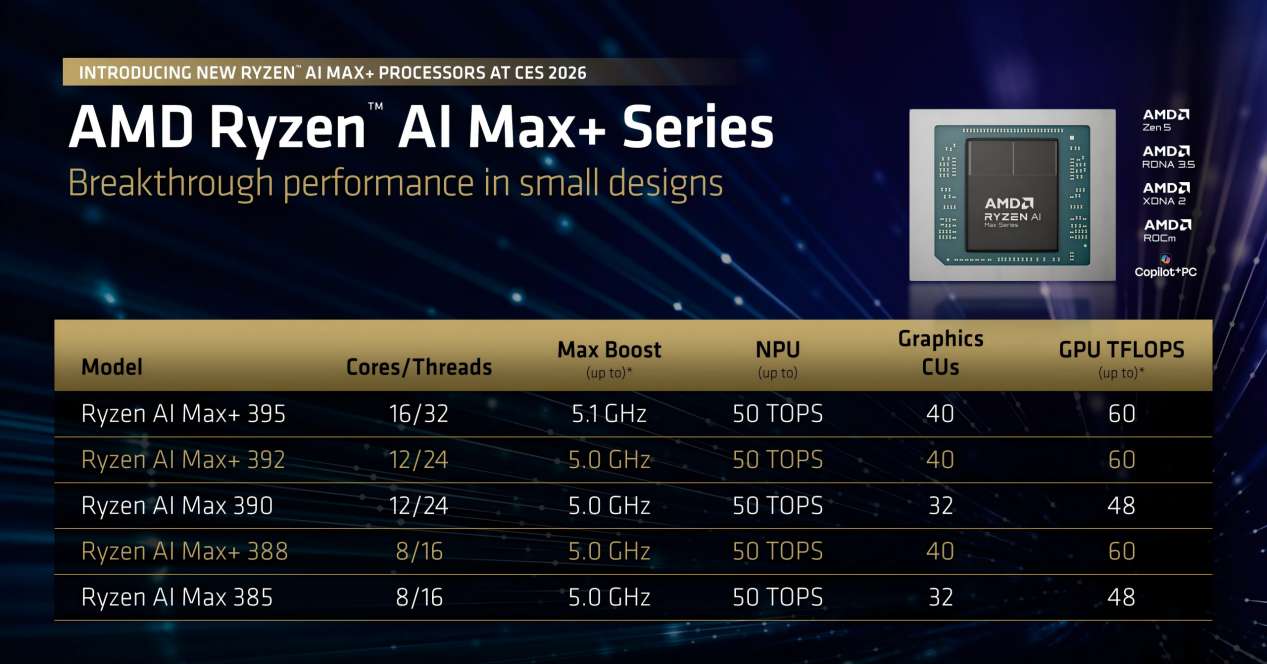
就在CES 2026上,AMD发布了锐龙AI MAX+系列的两款新的SKU——锐龙AI MAX+ 392和锐龙AI Max+ 388,可以看到这两款产品均采用了与旗舰锐龙AI Max+ 395相同的AMD Radeon 8060S超强集显与50 TOPS的NPU配置,仅是在核心、线程数上有所区别。按AMD的产品路线图规划,这旨在扩展锐龙AI MAX平台在更多场景和产品形态上的更多体验。
是的,就像Jack强调的,Strix Halo并不只是一个“性能很强的游戏盒子”,最强集成显卡的“下放”,能够让轻薄笔记本电脑也可以搭载锐龙AI MAX平台的产品,提升AI PC在AI本地化部署与游戏场景的能力。就在发稿前,我们已经了解到不少AI PC已经确认搭载锐龙AI MAX+ 392和388处理器。
eFashion:您在IFA 2025上提出,AMD的首要任务是为“完美PC”提供软件和硬件。您认为完美的AI PC应该具备怎样的形态?

当话题转向“完美PC”时,Jack Huynh并没有给出一个理想化或概念化的定义,而是从非常务实的角度出发:先把PC本身做到极致,再谈AI的叠加。在他的表述中,完美PC首先意味着高性能、优秀的能效表现、成熟的工业设计以及可靠的日常体验,这些传统PC的核心指标,并不会因为AI的出现而被弱化,反而应该成为AI PC成立的前提条件。
如果将这一标准具体对照到AMD目前已经落地的产品上,会发现“完美PC”并不是一个抽象口号,而是可以被拆解验证的。以锐龙AI处理器为例,它并不是单纯围绕NPU算力展开设计,而是通过CPU、GPU与NPU的异构协同,让不同类型的负载运行在最合适的计算单元上。CPU负责通用计算和响应速度,GPU覆盖图像、高并行和创作类任务,而NPU则以极低功耗承担重度 AI工作负载。这种分工,使得AI能够真正成为一种“常驻能力”,而不是偶发调用的功能模块。
再进一步看Strix Halo 即锐龙AI MAX平台,其实更能体现AMD对“无妥协PC”的理解。AMD UMA统一内存架构让CPU、GPU和NPU共享同一套高带宽内存资源,这不仅提升了AI推理效率,也避免了传统异构平台中频繁的数据搬运和性能损耗。从工程角度看,这意味着在运行AI工作负载时,整机并不会因为资源调度问题而出现明显的体验割裂。
如果以Mini AI Workstation这一形态为例,它在体积、功耗受限的前提下,依然能够同时满足高性能计算、本地AI推理和相对可控的能耗表现。从“是否符合完美PC”的标准来看,这类产品至少在特定使用场景中是成立的:它在极小的空间内,没有为了AI牺牲基础计算能力,也没有因为追求性能而忽视能效和稳定性。

当然,如果把“完美PC”放到更广义的消费级市场中,AMD的策略也显得更加理性。Jack多次强调,硬件只是体验的一半,另一半来自操作系统、应用生态以及与合作伙伴的协同。这也是为什么AMD并没有急于通过某一代产品去“定义”AI PC,而是选择通过平台化设计,为未来尚未完全成型的AI应用预留空间。
而在CES 2026的主题演讲中,AMD已经展示了一些未来AI应用的雏形,在Jack看来,这些只是开始。AI仍然处在非常早期的阶段,AMD当前的策略,是通过平台级的设计,为未来更丰富多形态的AI应用提前做好准备。
从这个角度看,当前的锐龙AI处理器产品,更像是“通往完美PC的阶段性成果和形态”,它们已经在性能、能效和AI架构之间建立起相对合理的平衡,也在工程层面证明了AI可以自然融入PC的既有使用逻辑。至于是否真正达到“完美”,或许还需要更多软件和应用的成熟来共同完成,但至少在硬件和平台层面,AMD已经把地基打得足够扎实。
eFahion Says:
在Jack心目中,“完美PC”正是通过AMD在每一代产品上不懈努力去逐步实现的,或者我们可以换一个说法——“无妥协PC”,才是当前走向完美的正确解法。今年的锐龙AI处理器产品,是AMD基于过去的市场趋势与用户反馈做出的最新一步调整。

当然,真正的完美PC是一个完整生态,而不仅是一款产品,需要像AMD这样的领头羊带动整个软硬件体系、整个AI架构共同前进。在出色硬件产品的背后,AMD搭建了像ROCm这样的跨平台统一软件栈,它能够在AI时代帮助AMD硬件实现更强大高效的应用体验。
eFashion:各家AI PC的芯片厂商一直都在提升NPU算力,但除了Windows 11的Copilot+功能以外,一直都没有“杀手级”的应用能够让普通消费者将其长时间、高频度地用起来,那么未来AMD NPU的演进路线是怎样的?

这是一个非常现实,甚至略显尖锐的问题,而Jack Huynh的回应并没有回避这一现状。他坦率地指出,AI PC仍然处于一个非常早期的阶段,无论是应用成熟度还是用户的认知,都还没有走到那个爆发点。
在Jack看来,目前外界对于NPU的讨论,往往过度集中在算力指标上,但这并不是问题的核心。真正重要的,是NPU所代表的一种计算逻辑:以极低功耗,长期、稳定地运行高频AI任务。这也是为什么AMD会坚定地认为,AI PC必须拥有一个独立的AI引擎NPU,而不是完全依赖CPU或者GPU。
从工程角度上来看,这一判断其实非常务实。GPU虽然具备极强的通用并行能力,但功耗和发热决定了它不可能承担全天候运行的AI任务;CPU在灵活性上占优,但在能效比和并行度上同样存在明显短板。如果AI能力未来真的要做到像自来水那样“随时可用、持续运行”,那么NPU几乎是在端侧唯一合理的承载方式。
但问题也正如我们提问中指出的那样,为什么现在仍然缺乏“杀手级应用”?对此,Jack给出的答案并不是“应用很快就会出现”,而是强调这是一个需要耐心的整个生态链携手并进过程。AMD当前正在与生态伙伴共同规划一个3到5年的演进路线,一边推动硬件能力成熟,一边等待软件形态真正跟上。
同时在场的AMD公司副总裁兼客户端渠道业务总经理David McAfee先生也补充提供了一个更贴近产业现实的视角。他指出,当前已经有不少AI能力正在悄然向NPU迁移,例如部分本地生成、私有化AI以及一些强调隐私保护的应用。这些应用未必具备“爆款”属性,但它们正在完成一件更重要的事情——验证NPU在真实使用场景中的价值。
但从用户业角度来看,“杀手级应用”的出现固然可以在短时间内激起用户对AI PC的需求,但当AI的发展路径像互联网、云计算、5G那样由稀缺到泛在,成为像高速路、自来水一样普遍可及的公共产品时,是否爆款已经不再是需要纠结的问题,有与否才是造成体验差距的关键,因为那时AI能力和算力将会以用户难以察觉的方式,默默在后台处理一切AI相关的负载。就目前日益涌现的AI应用发展态势来看,可以预见这一天的到来应该也不远了。
这正如David所强调的,一旦AI应用被迁移到NPU上运行,其意义是根本性的:它可以在几乎不影响续航的前提下,长期驻留在系统中。这种“无感知”的AI才是未来AI PC真正的使用形态,而不是偶尔唤起的一次性功能。
Jack也用生成式AI的演进过程做了一个类比:从最早的文本生成,到图像,再到视频,而现在已经开始构建完整的“世界”。这些能力最初几乎全部诞生于云端,但随着模型效率和硬件能力的提升,最终会下沉到本地设备上。在这一过程中,NPU并不是为了当下而存在,而是为了迎接这些变化的到来和普及。
如果从这个视角重新审视AMD的NPU路线,会发现它并不是一条激进的“性能竞赛”路线,而是一条强调能效、常驻性和生态成熟度的长期路径。它的发展路径也非常清晰,带动整个行业共同完成硬件、软件和应用层的进化,推动AI算力成为泛在可及的、像自来水一样普遍的基础设施。
eFashion Says:
回看这次交流,AMD并没有试图给出一个关于AI PC的“标准答案”。无论是Strix Halo在中国市场催生出的Mini AI Workstation,还是对“完美PC”的定义,AMD更是在反复强调一种底层逻辑:AI不应该重塑PC的使用方式,而应该自然融入其中。
从已经落地的产品来看,搭载锐龙AI、和锐龙AI MAX系列处理器的产品并不能被简单地称为“完美PC”,但它们至少展现了一种可行路径——在不牺牲传统PC体验的前提下,引入真正可用、可持续的本地AI能力,这反而显得难得。
至于NPU和所谓“杀手级应用”,或许本就是不该纠结的问题。AI PC的真正拐点,可能并不是某一个现象级应用的诞生,而是当AI功能开始变得足够普通、足够低功耗、足够稳定,以至于用户不再意识到它的存在。持续投入一步步地创造并奠定基础
而AI PC是否真的会走向“完美”,答案或许并不在芯片厂商手中,而在于整个生态是否能够持续投入时间和努力,在这条路上一直创新并实现自我超越,不断解决用户新涌现的痛点,那样“完美 PC”就会离我们越来越近了。
让我们一起期待这一天!


加载更多