

进击的AMD
ZEN架构技术交流会后的微架构分析

AMD首席执行官Lisa Su公开更多关于ZEN的信息。

AMD首席技术官Mark Papermaster讲解ZEN的IPC提升了40%

AMD全球市场营销副总裁 John Taylor演示Zen处理器在4K分辨率下流畅运行游戏大作

3.0GHz ZEN处理器工程版与3.0GHz Core i7 6900k进行的同频性能对比,结果显示ZEN处理器的渲染速度要更快一些,在Blender 3D软件中的渲染耗时要少于Core i7 6900k。


ZEN希望在不提升功耗的前提下提升IPC ( 即CPU每一时钟周期内所执行的指令数),采用了14nm FinFET制程工艺。

ZEN只是起点,未来还有ZEN+。
据悉,ZEN处理器的消费级产品代号为SUMMIT RIDGE,具备最多8核心、16线程设计,其AM4平台将可支持DDR4内存、PCIe 3.0总线,以及下一代的单芯片主板芯片组。同时AM4平台配套主板将支持USB 3.1、NVMe SSD、SATAExpress等最新存储技术。不仅如此,AMD在分支预测、高级数据预取、降低缓存延迟方面都做了相当多的努力。而14nm FinFET制程的加持,也让功耗控制毫无问题。到底AMD是如何实现质的飞跃的呢?我们接下来将对ZEN的微架构进行全面的分析。
自从Intel在2006年全面推出Core家族处理器以来,AMD就面临了比较严峻的挑战,从K8到K10再到Bulldozer系列都无法有效阻止Intel的进攻。在此期间,不断有传闻称AMD将放弃此前的Bulldozer系列,开发一个全新的微架构试图追回差距。日前,传言已经证实,全新的Zen微架构公开亮相。
回顾Bulldozer
当年AMD的Athlon/Athlon X2对英特尔Pentium4的成功,一直被认为是AMD漂亮的翻身仗。但在英特尔酷睿微架构于2006年面世后,从技术面上来说AMD就开始陷入被动,K8架构后期和此后推出的过渡性K10系列产品都没有能阻止对手,到了2010年的时间节点上,AMD面临的压力更大,如果这个时候没法推出一款能够与Core系列竞争的芯片,在市场上的发展空间就会被挤压。
这个时刻的AMD有两个选择:继续在传统乱序多发射的结构上不断调校,与Intel硬刚正面;或者冒更大的风险,探索全新设计思路带来的可能性?勇敢的AMD选择了后者。
Bulldozer推土机架构就是AMD六年前给出的答案。它诞生于2010年,临危受命成为全新一代AMD微架构,并且是服务器市场和桌面PC市场统一使用的微架构,一荣俱荣,一损俱损。其竞争对手是英特尔的SandyBridge。英特尔在抛弃Netburst架构后启用了原先为笔记本平台研发的酷睿微架构,胜过了AMD,而AMD用更加激进的姿态拿出了一个背离业界传统的架构。这个微架构的新颖性无可置疑,比英特尔当初吹响反攻号角的酷睿微架构还要新,即便放在六年后的今天,也难以找到与Bulldozer非常相近的设计。
和当时已经获得业界广泛采用的同步多线程不同,Bulldozer硬是独辟蹊径,将原本在传统乱序多发射 + 同步多线程中共享的寄存器重命名、指令发射、执行单元等部件都做成了独立的,但负责指令供应的前端仍然保持与同步多线程相同的共享状态。这样一来,操作系统就会把一个Bulldozer模块看成两个执行核心,在对比吞吐量时,Bulldozer就可以凭借更多的独占资源胜过大部分或绝大部分资源都处在共享状态的同步多线程设计—至少理论上如此。从架构的创新性来说,Bulldozer在片上多核、同步多线程、片上多线程之外又开辟了一片新的空间,如果AMD能够把这种设计贯彻到位,它可以具备比SMT更好的单线程性能,同时又在吞吐量上领先。
但事与愿违,从Bulldozer的最初设计上,就有一些明显的异样证明AMD并未打算在Bulldozer上推高单线程性能、或者有这个意愿但是执行并不到位。例如,两个核心共享的前端面临的指令供应压力是比较大的,AMD也的确给了两倍的指令缓存容量和指令缓存读取带宽,但是指令缓存的组关联度却只有2路,解码器也只设置了4组,并且两个执行后端中的每一个单独拉出来都比酷睿的核心要弱。这样来看,AMD在当年的PPT上强调只追求到keen-of-the-curve也就有了合理的解释:Bulldozer更加偏向于多线程吞吐量优化而非IPC优化,这使得基于Bulldozer结构的芯片在常见的单线程测试中都落后于基于SandyBridge的产品。
从六年后的今天来看,Bulldozer的研发更像是一个预测:预测在2010年以后,多线程吞吐量的重要性会胜过单线程性能;预测在这种全新的、不同以往设计的结构可以有胜过SMT的吞吐量表现。
然而,在预测的时间点错了的情况下,第二个预测已经无法证实。但公平地来说,Bulldozer虽然在商业上并不算特别成功,但在技术上的进取和革新却非常值得称道。对于线程级并行度的发掘手段,业界一直没有特别一致的共识。且不说IBM和英特尔这两个同样使用片上多核+同步多线程的设计都有明显区别,就连IBM自己的Power系列,从Power5到Power8一路走来对于单线程性能与多线程吞吐量的平衡点也在一直变化。Bulldozer用巨大的代价探索了一条不同于以往的崭新设计思路,可以说是非常有意义的。
TIP:片上多核(CMP)、同步多线程(SMT)、片上多线程(CMT)
从高层次结构上来说,片上多核、同步多线程、片上多线程都是提高吞吐量的常见设计。它们的区别是:片上多核通过集成多个核心来提高吞吐量,这种设计的核心一般也具有最强或者较强的单线程性能;同步多线程通过一个核心内部同时运行多个线程来提高吞吐量,因为一个核心内部的执行资源被多个线程共享,单线程性能会出现一定程度下滑;片上多线程的经典代表是Sun的UltraSPARC T1,这也是一种比较少见的设计,其核心内部发掘指令级并行度的能力很弱,基本上完全依靠在多个线程之间切换、发掘线程级并行度来重叠高速缓存缺失之类的长停顿事件。目前Intel/IBM的芯片同时使用多核和同步多线程两种设计。
Zen:回归传统轨道
六年以后,AMD终于决定在Bulldozer和后继改进型号后,推出另一个全新的微架构。从市场环境来说,Zen面临的任务比推出Bulldozer时更加艰巨,那么Zen能不能击败对手,为AMD带来更光明的未来?
重压之下,AMD等到了这个第二次对决机会。这一次AMD没有再选择像Bulldozer一样激进,而是选择了一个久经考验、各方面都经过验证的传统设计路线 — 强有力的乱序多发射与同步多线程的组合。
从设计上看,ZEN架构和酷睿系列微架构有异曲同工之妙。4发射设计,两路SMT支持,微指令缓存(uop cache),甚至连许多结构设计点的参数选择都非常接近。

AMD于2010年8月在Hotchips上公布了Bulldozer

Bulldozer架构图

Bulldozer拥有更多的独立资源
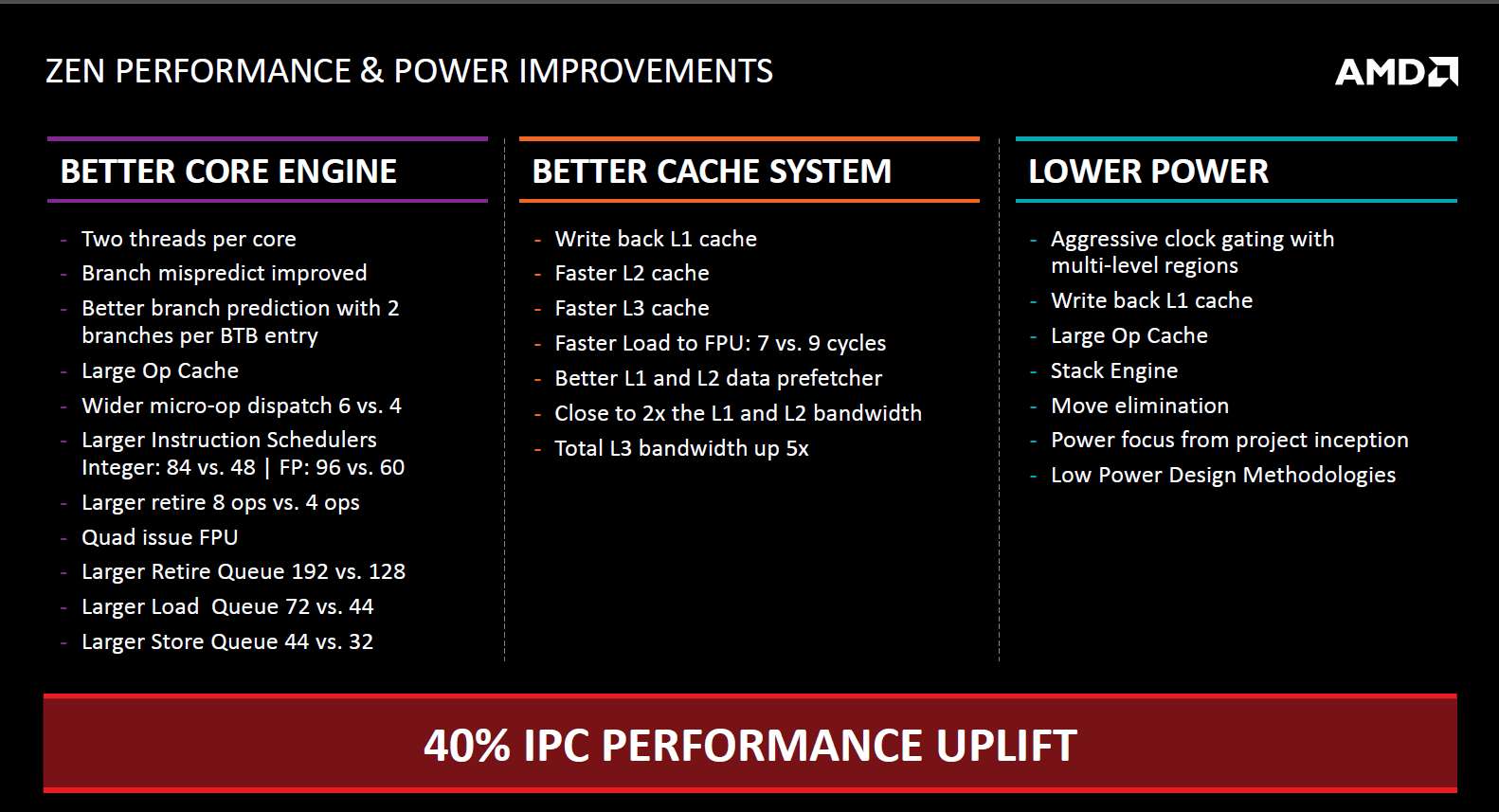
今年Hotchips上公布的ZEN主要改进点,宣称IPC可以提高40%
决定乱序执行窗口大小的关键指标之一重排序缓冲区,ZEN与Haswell同为192项,Skylake为224项。在决定缓存数据访问能力的关键指标Load/Store队列上,ZEN与Haswell完全一致,在乱序执行引擎中负责保存操作数的寄存器堆容量上,ZEN与Haswell也基本持平。在乱序执行引擎中负责保存待发射指令的保留站上,ZEN领先于Haswell。总体来说,各项参
数基本处于Haswell和Skylake之间。
在微结构内部各种关键性资源的额定容量相近的情况下,重点就落在了设计细节的比拼上。
例如,在重排序缓冲区容量接近的情况下,指令聚合技术可以把符合条件的多条邻近指令聚合成一条,作为单个指令对待,从而节省了微结构后端的各种存储容量。目前已知英特尔和AMD都拥有指令聚合设计可以令多条指令共享微结构资源,获得超越额定容量的效果,AMD一方的指令聚合设计是否能战胜Intel尚不清楚,值得期待。在load/store队列上,即便容量相同也有很多可以提高性能的设计点,例如load/store地址的反别名分析。目前Intel的处理器配备了比较激进的反别名分析,可以在load/store地址别名分析尚未完成的时候就推测性地发射,虽然AMD在自己的PPT中并未提及这一点,但笔者预计AMD也实现了类似能力。再比如load/store队列上还可以进行store到load的数据转发,因为处理器内部的架构可见寄存器数目非常有限,(x64大约为十几个),寄存器数目不够用时,原先存储在寄存器内的数据就要通过store指令换出到缓存上,需要再用时再通过load指令装载回来,store到load的数据转发可以弥补寄存器换出时的性能损失。在保留站上,从目前资料看来英特尔仍然更激进。从酷睿微结构开始英特尔就一直坚持统一式保留站,而AMD的经典设计K8架构和现在的ZEN都是独立式保留站。这两种设计的区别是,独立式保留站设计容易,一般来说每种指令/每种功能单元口前放置一个独立式保留站专门处理对应类型的指令,但是容易出现容量不平衡,例如碰到整数密集型的应用时浮点指令保留站会空闲,而整数指令的保留站会很繁忙,碰到浮点密集型的应用时整数指令的保留站就会空闲,而浮点指令保留站会繁忙。统一式保留站存储着所有类型的待发射指令,但设计难度大。现在英特尔已经实现了更大容量的统一式保留站,在这一点上,我们期待AMD未来的ZEN+可以继续优化一下。
总体上来看,笔者认为AMD ZEN很有希望达到其设计预期,因为原先Bulldozer的单核心被有意弱化,而ZEN的设计重点已经完全转移到单核心性能上来,因此40%的IPC提高是可以期待的。
核心流水线亮点介绍
ZEN的指令读取部分保留了Bulldozer的分离式分支预测的特点,分支指令的跳转预测超前于指令读取进行。在指令TLB上出现了比较激进的三级TLB设计,这是笔者目前所见的第一个使用三级指令TLB的设计,英特尔的Haswell使用单级128项的TLB,在双方均没有公布具体流水线级数的情况下,孰优孰劣不太好比较。
虽然是回归了传统,但ZEN的指令读取设计上也可圈可点。第一,使用了某种压缩BTB设计,让一个BTB保存两个分支,相当于将BTB的有效大小翻翻,同时保持相同的访问延迟。其二,指令缓存的配置是64KB、4路组关联,每周期32Byte的取指令带宽,而英特尔是32KB,8路组关联,每周期16Byte的取指令带宽。就笔者所见的测试数据而言,容量的影响大于组关联度,但不知道AMD的设计会不会导致频率受到影响。其三,微指令缓存(uop cache)的加入。英特尔从SandyBridge开始就加入了微指令缓存,到Haswell时已经发展到1.5K容量,32个组,8路组关联,每个缓存行存储最多6个微指令。到Skylake时,这6个微指令可以在一个周期内送给流水线的下一级,目前AMD尚未公布自己的微指令缓存的具体参数。
在指令解码上,除了此前提到的微指令缓存外,AMD还加入了一层微指令队列,位于微指令缓存-解码器之后、指令分派之前,推测是用于实现独立的循环缓冲区(loop buffer),在执行循环指令时最大限度地关闭前端来节省功耗,另一面也可以缩减实际流水线长度。在AMD的PPT上还提到了Branch Fusion,这一术语应该是指代指令融合中与分支指令有关的一种,一般来说是将分支指令与前后的指令融合起来,例如分支指令 – 算术指令可以融合成谓词算术指令。比较令人注意的是,负责store到load转发的memory file居然放在了解码阶段上,仔细思考了一下发现这可能是一个比较妙的设计,因为解码之后的寄存器重命名时就可以携带上转发的数据,可能比放在执行后端、靠近load/store队列的做法要好。
从执行阶段来看,6分派6发射,四个整数执行单元的结构令ZEN的整数执行能力保持完好,每个周期可以执行两条分支指令、对高发射宽度下的分支预测以及分支指令聚集的情况会有所帮助。比较引人注目的是8-wide retire的描述,推测这么宽的retire设计是为同步多线程准备的。
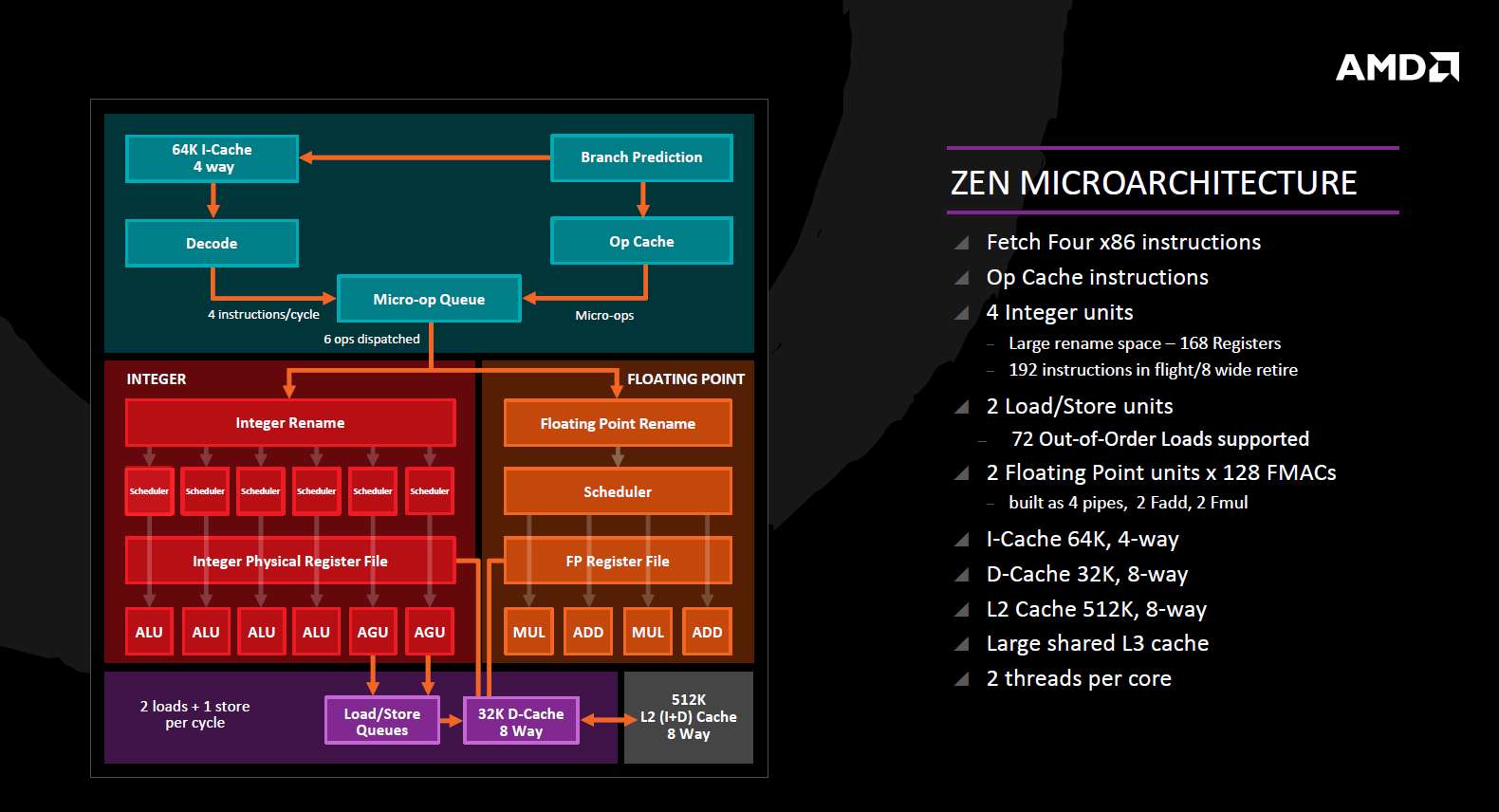
ZEN的微结构
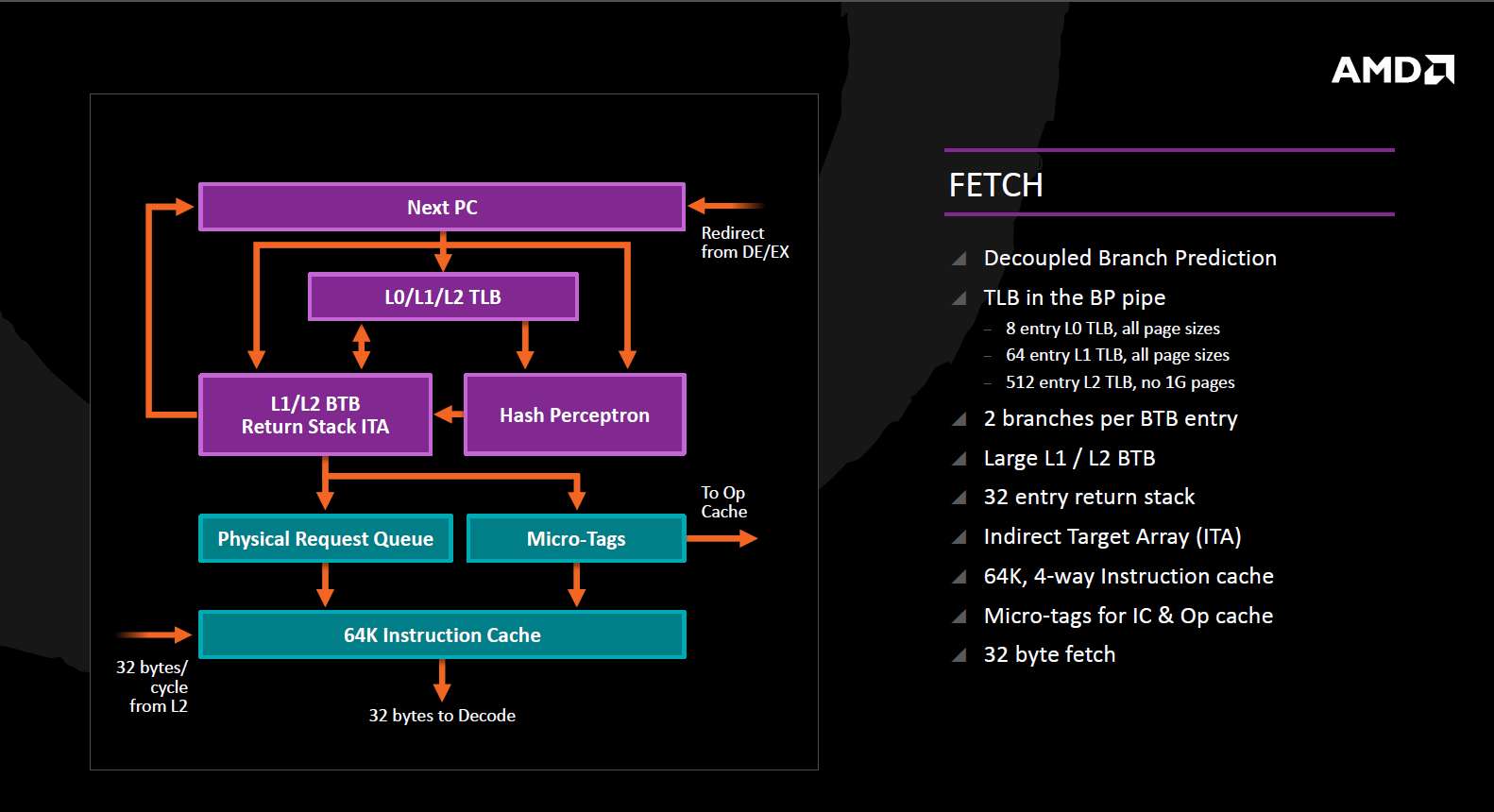
指令读取
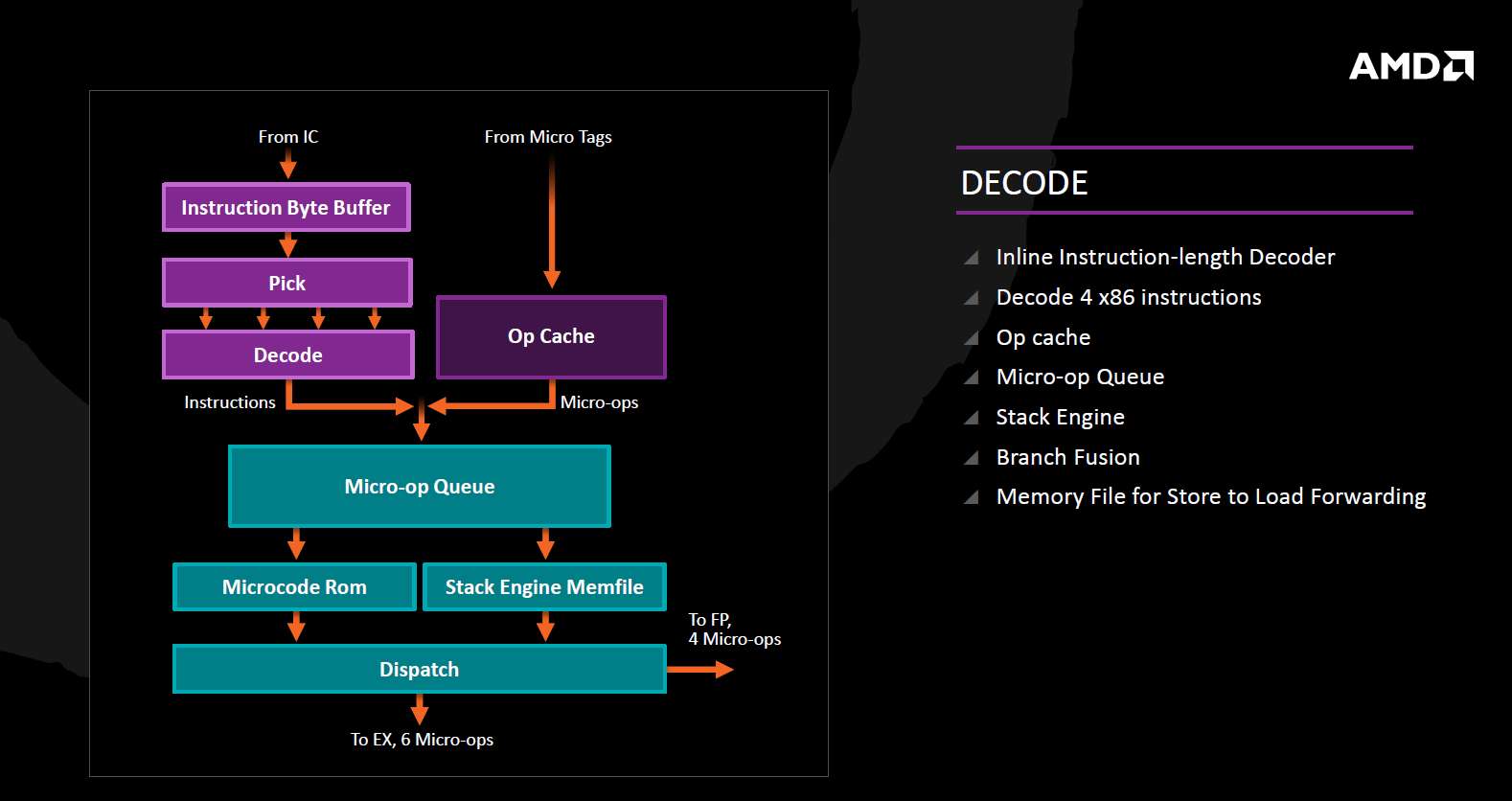
解码阶段
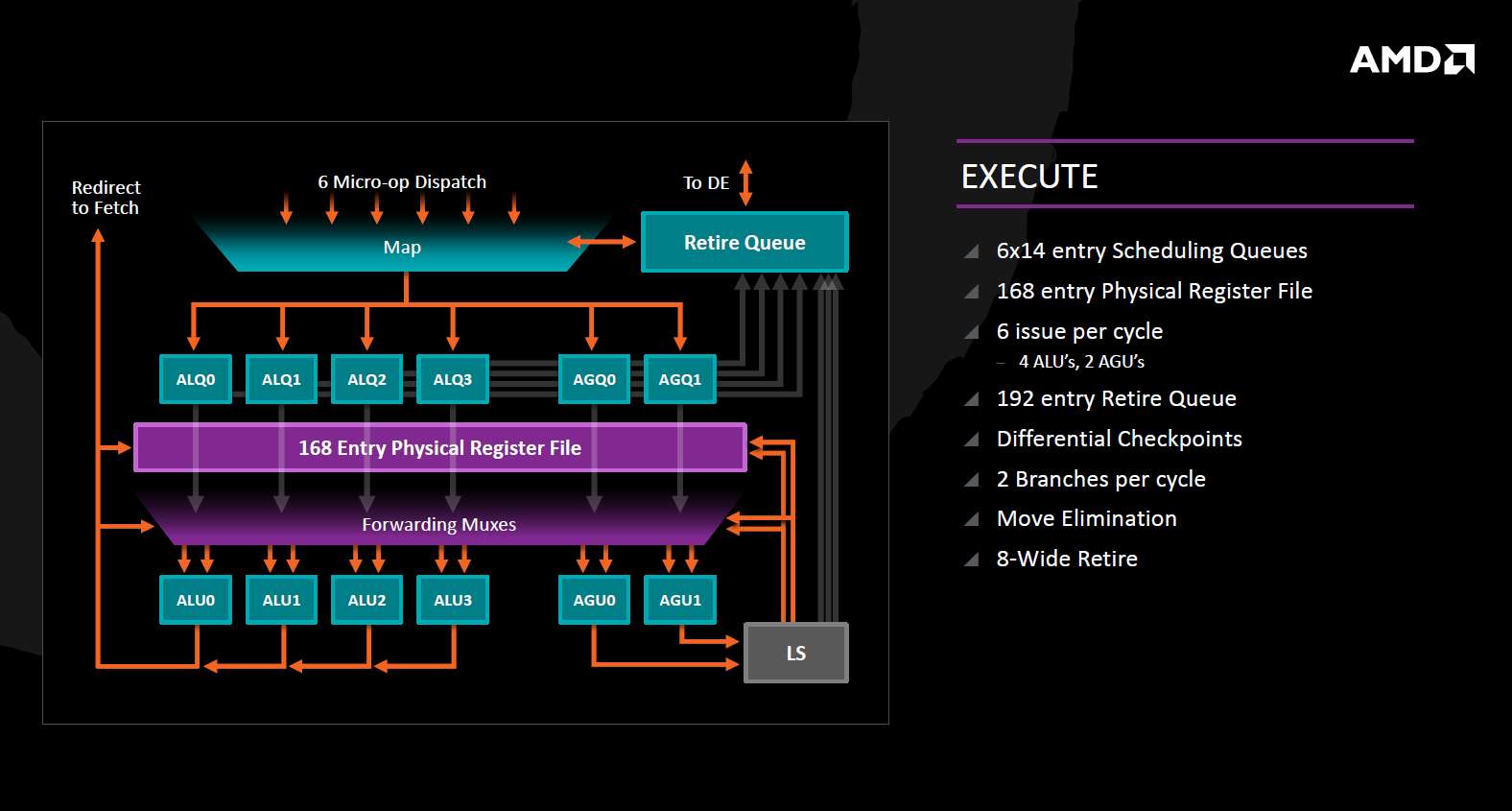
执行阶段
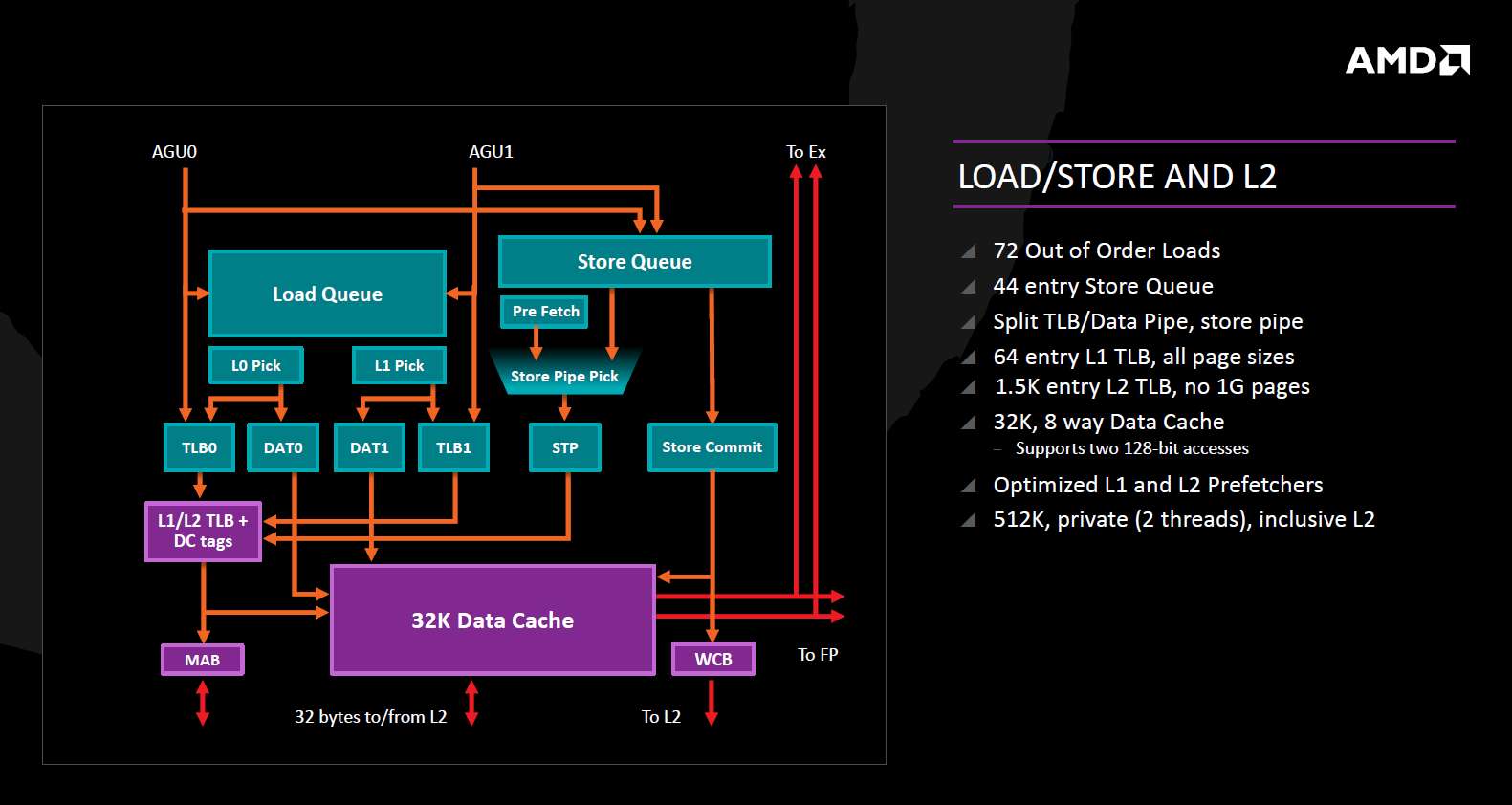
Load/Store和二级高速缓存
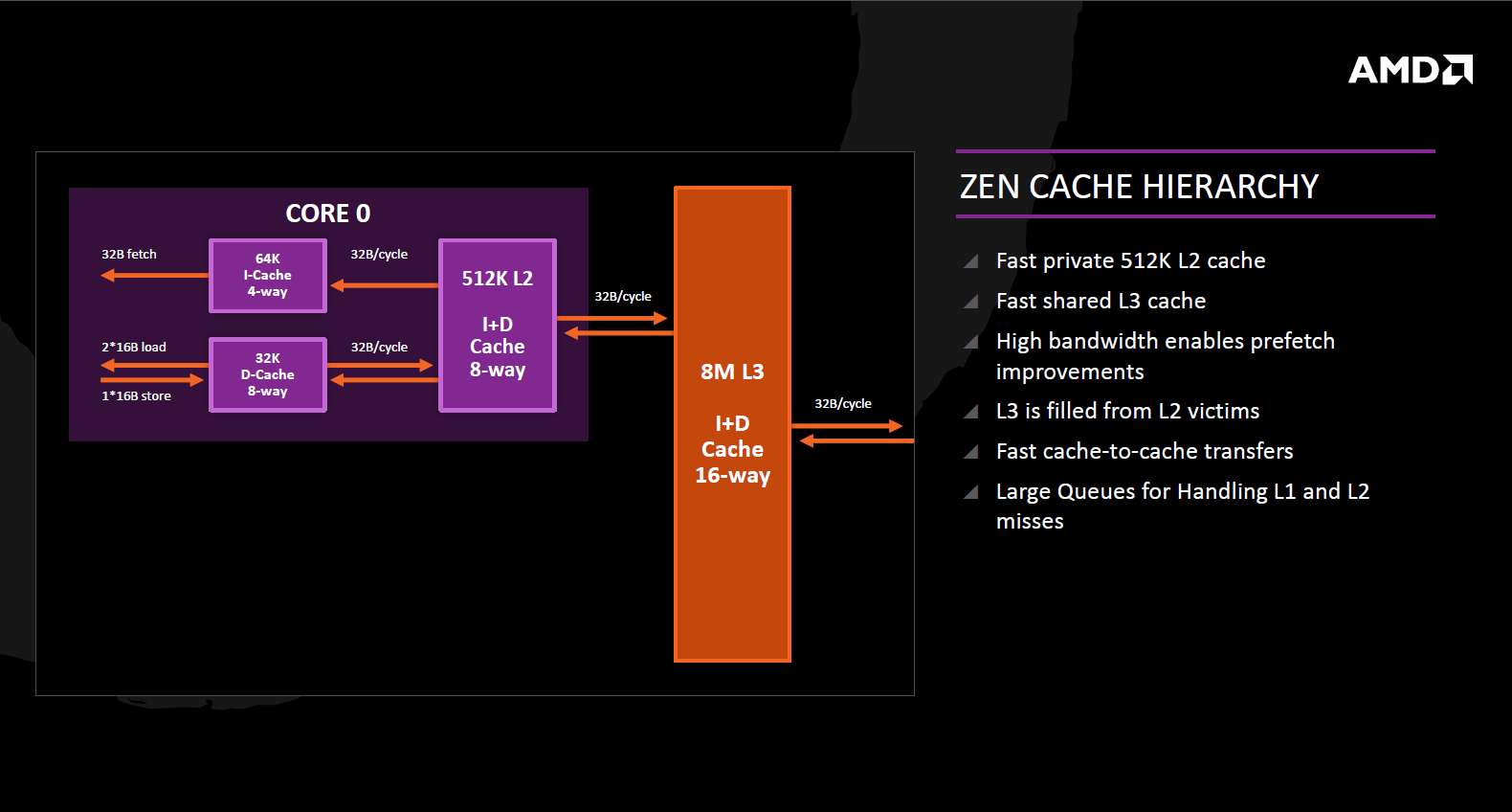
ZEN的缓存体系

SMT概述
在数据TLB上,AMD ZEN为64项设计,与Intel Haswell持平,二级TLB为1.5K项,大于Haswell的1K项;一级和二级缓存分别有自己独立的预取器,一级缓存为32KB,8路组关联,一级缓存的访问带宽为2×16字节/周期,与SandyBridge齐平但落后于Haswell的2×32字节/周期,二级缓存大小为512KB,同样为8路组关联,领先于Haswell和Skylake,但带宽32字节/周期落后于Haswell。值得注意的是,ZEN使用的三级缓存是一个大号的victim cache,容量为8MB,16路组关联,只切分了4个bank,并且没有做hash处理。PPT上说这个三级缓存只由二级缓存踢出的数据来填充,如果严格从字面意义上解读这句话,这就是说从内存上来的数据可以直接取到二级缓存上,只有被从二级缓存踢出时才会进入三级缓存。但图中又画了从三级缓存到下一级存储的双向箭头,暗示三级缓存也可以主动存储从下层上来的数据。此外,32字节/周期的带宽也不算高,三级缓存使用的互联结构也比较简单,相信ZEN+会在这一块予以补足。
在SMT的层面上,ZEN对各个部件的共享和控制会直接影响到单线程性能和吞吐,根据这个PPT里面公布的情况,ZEN使用的SMT控制方案和Intel比较类似,绝大多数部件停在共享状态,只有前端的微指令队列、中间的重排序缓冲区,以及后端的store队列做了静态划分(一般是一分为二),是一个比较成熟稳健的方案,此外,所有的执行资源在单线程模式下都是开放的,从理论上来看ZEN的SMT层面上将有望与Intel的Haswell层面一较高下。
总结:返璞归真
对比Bulldozer的激进创新,ZEN褪去了过于新颖的思想,重新回到了基于成熟和稳重的创新道路上,性能也迎来了跨越式提高。AMD的产品将再次以Intel强有力竞争对手的面貌出现在市场上,值得期待!
AMD总部探访
在旧金山参加Zen架构技术会议后,在AMD全球市场营销副总裁John Taylor的组织安排下,我和另一位中国同行参观了AMD位于美国加州桑尼维尔的总部。AMD公司成立已经47年,将近半个世纪以来,其总部一直都在美国加州桑尼维尔市。这也可能是中国媒体到这里的最后一次拜访,因为期间AMD Radeon技术事业部高级市场总监Chris Hook告诉我们:“你们大概是最后一批参观这个总部的媒体了,下个月我们就搬家啦!”原来,AMD即将搬到加州圣克拉拉和Intel、NVIDIA、高通等做邻居了,尤其是距离Intel只不过区区800米。




本次拜访活动由AMD Radeon技术事业部高级市场总监(AMD RTG Senior Marketing Director) Chris Hook 全程接待。

AMD VR Demo部门技术员Eric Szymaszek带笔者参观了AMD在办公区专门设立的VR体验区。包括HTC Vive以及Oculus等虚拟现实设备都可以在现场看到,适用于VR的游戏也几乎是应有尽有。很显然,AMD十分看重VR的前景,而且AMD是既有处理器又有显卡的品牌,未来在VR设备和应用程序的支持方面,相信会走在前面。

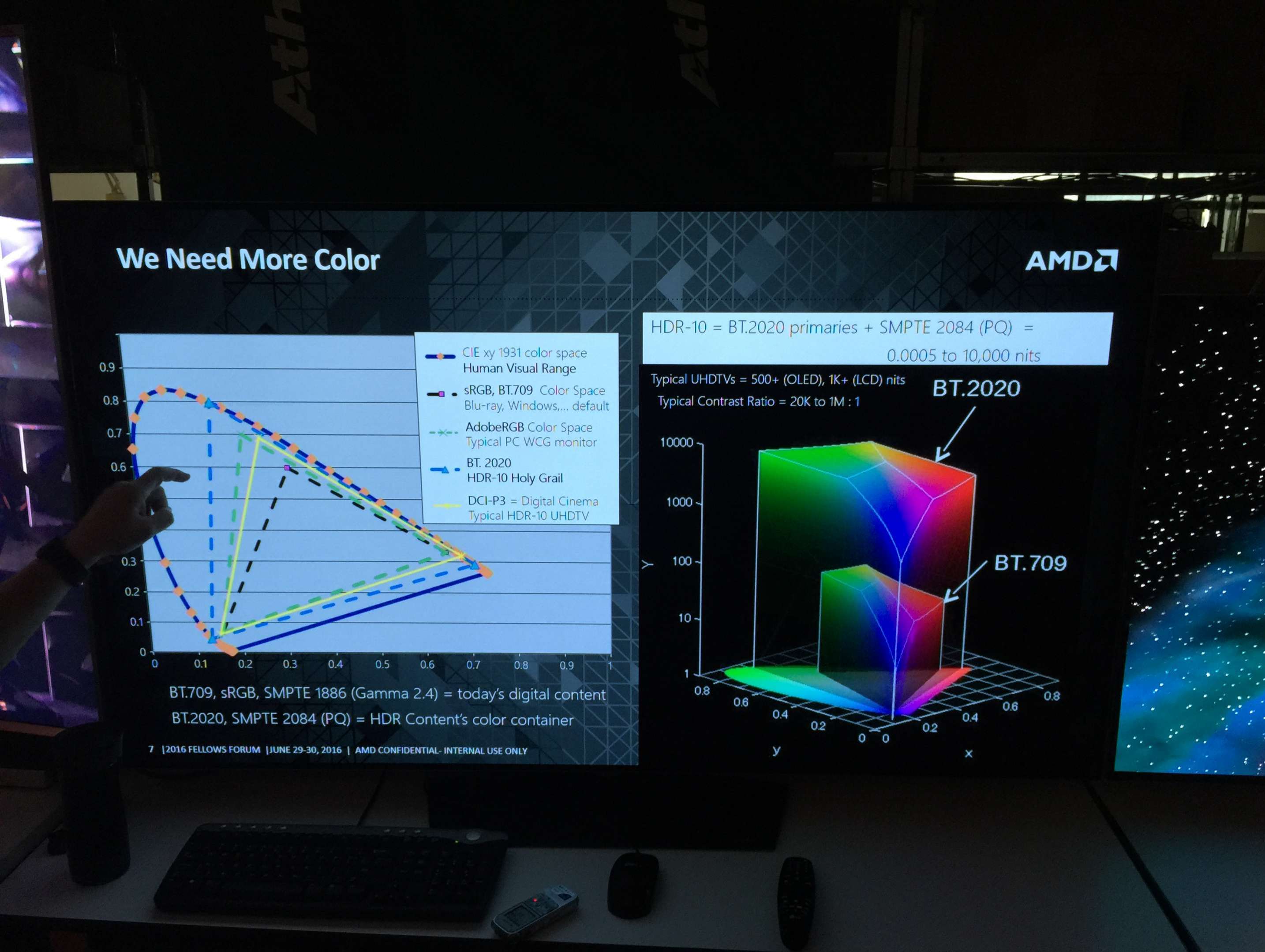
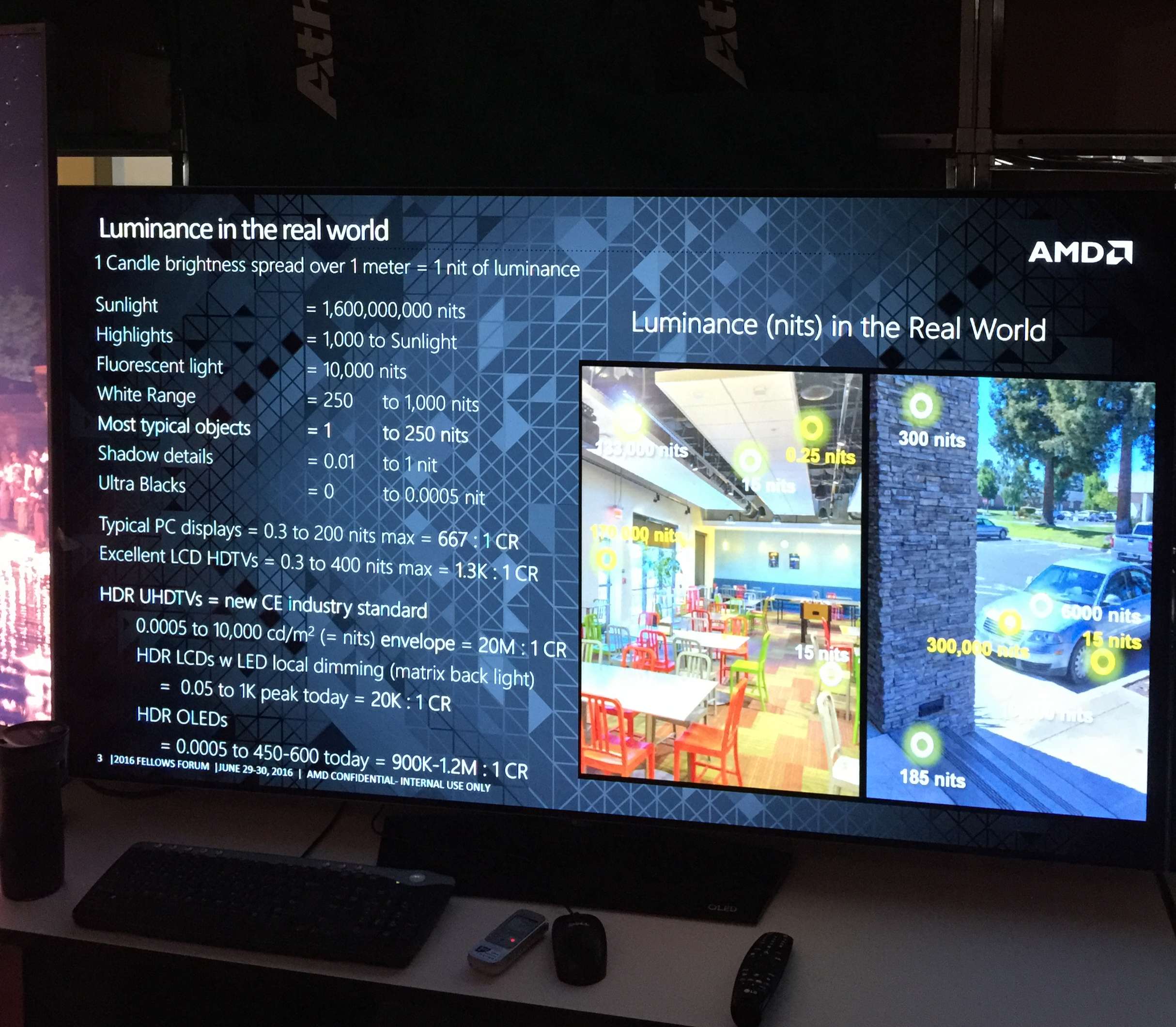
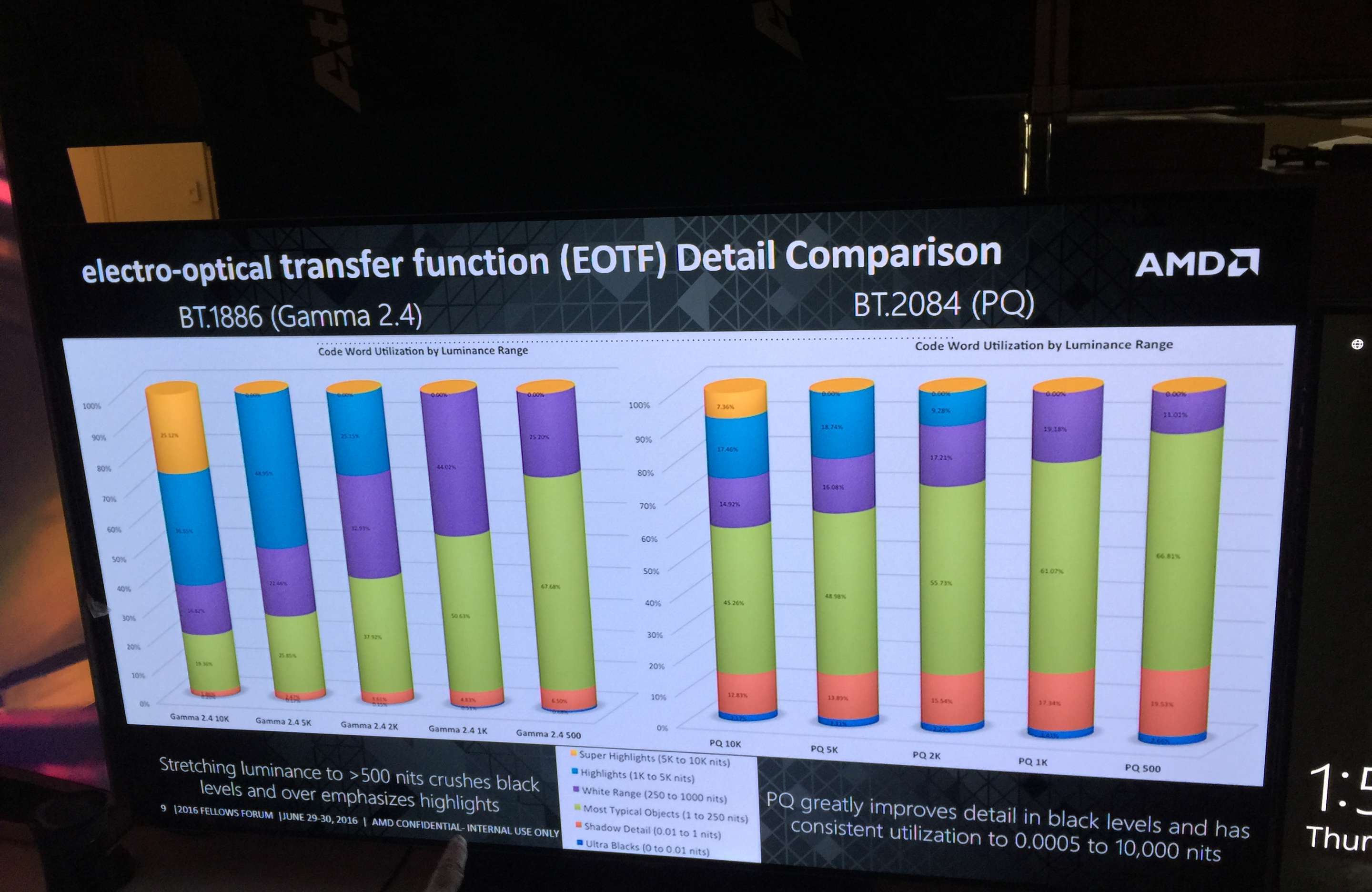
我们知道,无论图片还是视频,如果在标准动态范围(SDR)下显示,那么它的亮度范围只能在0.05-100nits之间,而在高动态范围(HDR)下,则可以达到0.0005-10000nits。这个范围越大,可以显示出的颜色种类就越多。最早,色彩范围的标准是针对CRT显示设备的,那时候能显示的色彩和细节很少,只有8位色,而现在AMD显示系统支持的12位色SMPTE ST 2084标准则可以突破人类可视范围,从而最完整地向用户展现像素和色域。而现在受显示器技术的限制,事实上并不能完全展示12位色SMPTE ST 2084标准的色彩表现,但AMD对高质量显示技术的投入却一如既往,因为显示设备的技术总会不断向前发展,而AMD已经提前做好了准备。


线框图在HDR下进行渲染

HiAlgo创始人尤金为我们详细说明其工作原理和演示实际使用效果

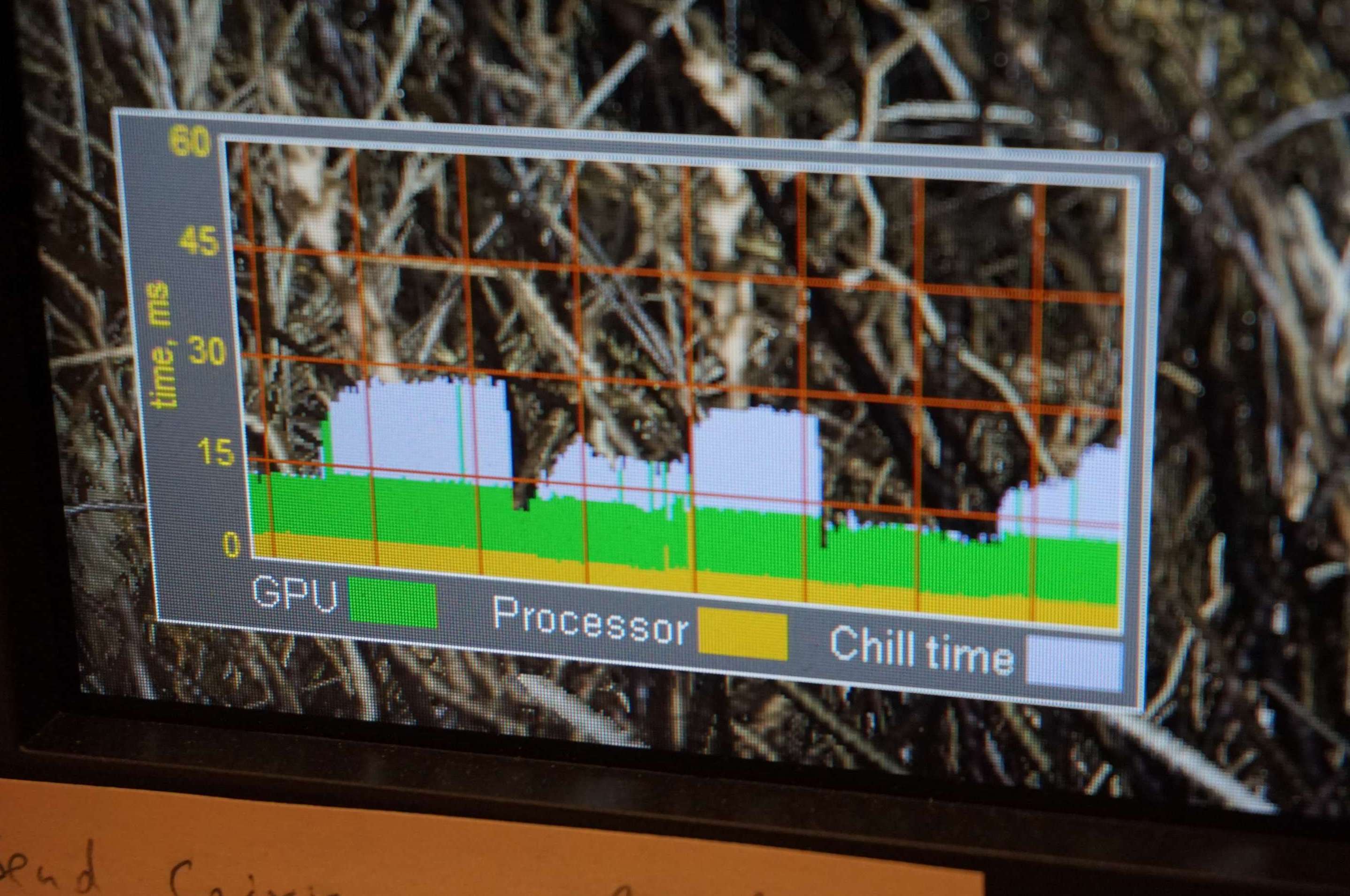
实际的渲染效果细节还原也很到位,右上角可以实时显示fps,记录表格里的Chill time为该插件为计算机所赢得的休息时间。
我们在AMD办公区中发现了HiAlgo的身影。这是一家专注于游戏优化的公司,而它的创始人尤金给我们介绍了其旗下有着著名的三件利器:HiAlgo Boost、HiAlgo Switch以及HiAlgo Chill。 HiAlgo Boost应该是相对应用比较广泛的一款软件了。它的工作思路非常巧妙,因为我们在玩游戏的时候,受限于硬件配置较低,经常碰到无法让我们同时享受优秀的画质与完美的流畅度。而有了这款插件,它能够通过获取鼠标移动速度,使分辨率和fps达到一个动态平衡。 也就是说,在移动的过程中,我们通常更加注意的是画面的流畅度而不是细节部分,所以它就会适当降低分辨率来换取更高的fps。而在静止的时候,我们希望看到精美的画面,这时它又会提升分辨率。这款插件目前支持DX9的大部分游戏,但不限于DX9,更多的需要玩家自己去尝试,开发者正在不断优化。 HiAlgo Switch则非常简单,它针对那些配置不高的电脑,通过一键切换,降低分辨率来换取流畅度。而HiAlgo Chill则与HiAlgo Boost相反,也是实现动态平衡,不过是在静态场景下,如果不需要高fps时,让电脑的GPU休息一会,以降低功耗与发热。 而现在HiAlgo已经被AMD收购,着力研发AMD所需要的技术,而这三大利器也很有可能以后直接整合到AMD的驱动之中。

Hialgo Technology 创始人尤金(Eugene Fainstain, Founder of Hialgo Technology )


加载更多